Defining Data APIs
Data Engineering
Purpose
The traditional boundaries between data engineering and software engineering have become increasingly blurred. Integrating data in the past required bespoke API integration with transformation logic before it even landed inside a companies ecosystem. Today we have a plethroa of cloud infrastructure and resources to manage data in a far more composable way. It’s now crucial to view the data warehouse and its surrounding infrastructure as a unified, deployable platform rather than disparate systems. However, in doing so this greatly increases the complexity in development of new and updating existing assets. This is a similar problem encountered in the majestic monolith software architecture. In this post, we’ll explore how to define interfaces within the data warehouse to better support the data engineering process.
Background
Data engineering involves transforming data to make it usable across various applications. In this context, we’re operating within a modern data stack using cloud resources and infrastructure. This post aims to provide a high-level overview of the data warehouse and its boundaries to establish clear contracts between different areas of execution in the data engineering process.
The Data Platform
Before diving in, it’s important to establish a common language. Different companies and even teams within the same company may use varying terminology. To ensure clarity, we’ll use the following glossary of terms throughout this post:
Glossary
| Term | Definition |
|---|---|
| Data Lake | A raw unstructured data store, often a copy of a data source in Snowflake or Files in S3 |
| Data Source | An internal or external production application data base or API |
| Integration | A service that ingests data (ie Fivetran, Snowpipe, Lambda etc) |
| Data Warehouse | A normalized (or canonical) data store, typically a database/schema in Snowflake |
| Staged Data | Not to be confused with a staging environment, this is canonical data |
| Exposure | A production data resource accessible by users and/or downstream systems or processes |
| Model | Encapsulated SQL code that uses Jinja templating to encapsulate transformation logic and manage dependencies |
Medallion Data Platform
The concept of medallion data is not new. However, its practical implementation can be ambiguous. The following sections present an interpretation of how to effectively implement medallion data concepts within a data engineering team, outlining the tiers of data coverage. While not definitive, this approach has proven effective in practice.
Tiers of Data
At its core, the medallion data platform consists of three tiers of data aimed at progressively reshaping data into more useful forms.
| Description | Tier | Goal |
|---|---|---|
| Raw Data | Bronze | Copy of a data source within the data lake |
| Canonical | Silver | Lightly transformed data moved to the data warehouse |
| Production | Gold | Business focused exposures leveraged by downstream cosumers |
What this might look like in practice is as follows:
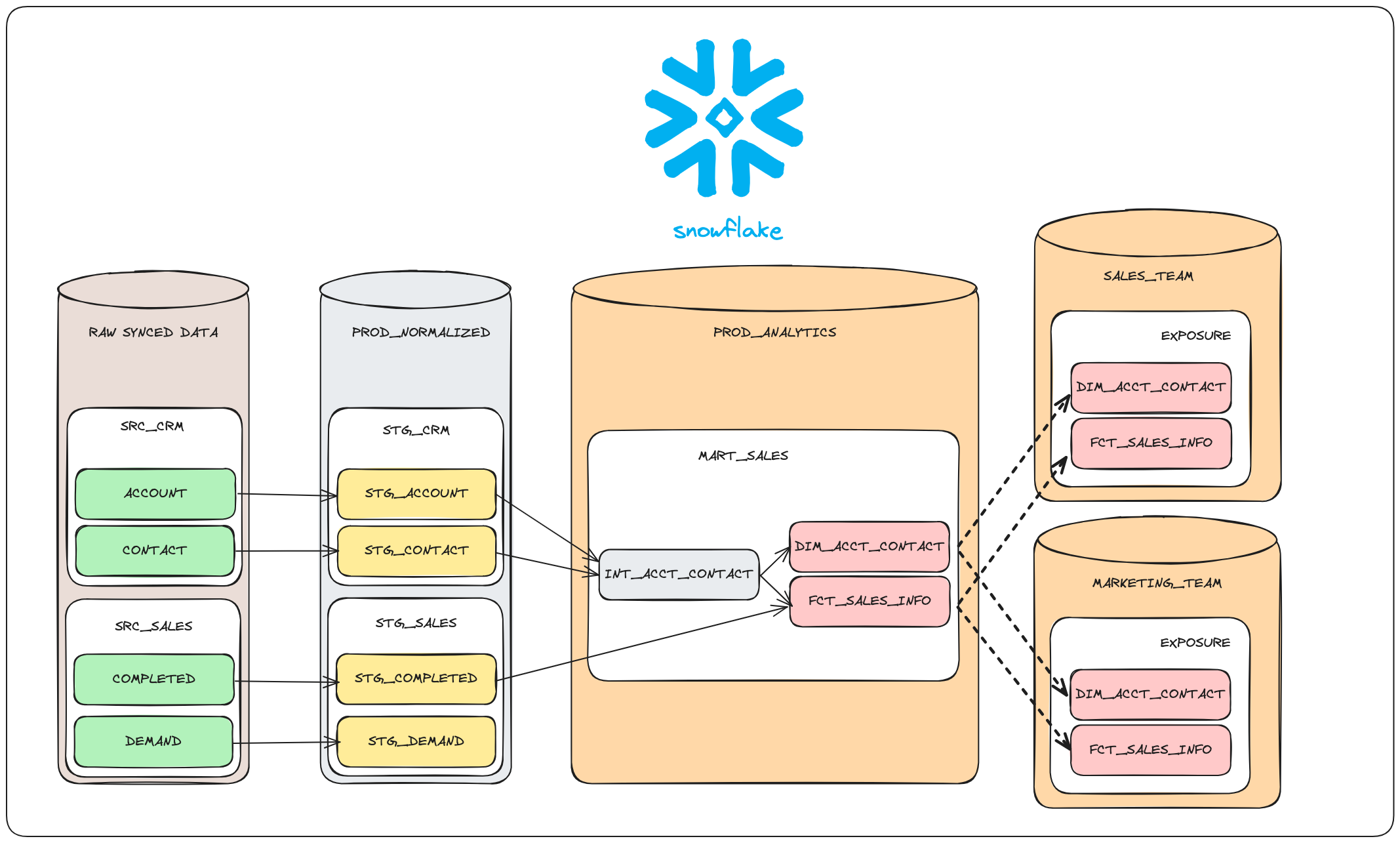
Data Boundaries
At their essence, boundaries serve as APIs, offering a reliable method for constructing intricate systems that collaborate without being tightly interwoven. They empower team members to interact with shared resources without impeding new developments or disrupting data flow within the system. Changes made within these boundaries are inconsequential to both upstream and downstream actors, as long as the established surface contracts remain intact. This principle closely resembles object-oriented programming or multi-service architectures.
In a modern data platform, we can readily discern four primary boundaries: Source, Integration, Transformation, and Exposure. While each will be explored in detail, here’s a straightforward illustration:
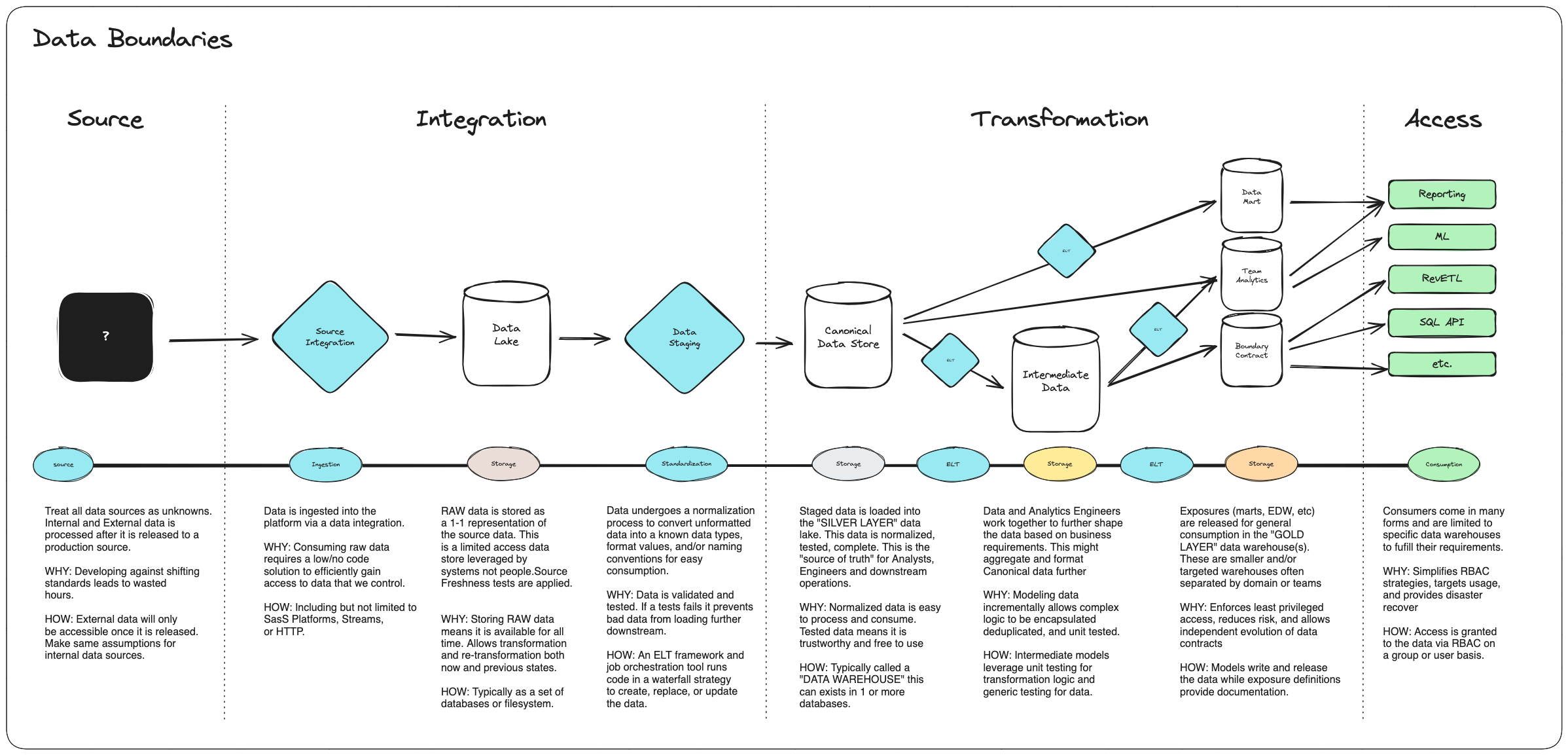
Data Sources
When constructing a data platform, it’s crucial to regard all data sources, whether internal or external, as black boxes. This approach establishes a loose coupling between the data platform and its sources, enabling the platform to evolve independently. Additionally, it dictates that only production data is ingested into the platform. This practice offers a secondary advantage: it ensures the accuracy and stability of all data within the platform, preventing development against unreliable or changing data sources.
Data Integration
Integration with a data source involves the process of bringing data into the platform. This is commonly achieved using tools such as Fivetran, Snowpipe, or custom code or SaaS applications. The key aspect of this stage is ensuring that all data brought into the ecosystem mirrors the data source exactly. This approach eliminates the need for complex ETL (Extract, Transform, Load) logic, reduces the number of custom connections required, and often speeds up the deployment time for establishing connections to the source.
Individuals or teams responsible for data ingestion focus on tasks such as understanding third-party APIs, configuring connections within vendor applications, and ensuring that all data is accessible to downstream processes in the platform. They do not need to worry about intricate transformation logic, downstream processing, or data storage designs. This approach allows systems consuming this data to optimize their data store designs based on their specific needs.
Transformation
Data transformation involves converting data from its raw format into canonical data. Canonical data warehouses serve as intermediaries between raw data and production data. This setup allows ELT (Extract, Load, Transform) engineers to refine, document, and standardize the raw data into a consistent and easily accessible format. The resulting staged data forms the basis for all subsequent production data transformations and represents the initial opportunity to validate, conduct integrity checks, and ensure data accuracy and stability.
Teams or individuals responsible for the transformation layer concentrate on bridging the gap between raw data and business requirements. They oversee the transformation logic and ensure that all Service Level Objectives (SLOs) and Service Level Agreements (SLAs) are met within the platform.
Access
Access to production data is primarily facilitated through downstream systems or processes, which serve as the gateway to what is often referred to as “gold layer data.” This gold layer data represents the interface through which all consumers interact with the platform. Contracts established at this tier are essentially treated as the platform’s API, setting the standards for how data is accessed and utilized. Therefore, it’s imperative to minimize breaking changes to these contracts or implement versioning to mitigate any potential disruptions to downstream partners, users, and consumers.
Individuals or teams responsible for the access layer play a crucial role in governing user access and permissions for data usage. They possess expertise in business requirements and oversee governance related to reporting and user access controls. Their responsibilities include ensuring that data access aligns with organizational policies, maintaining Role-Based Access Control (RBAC) mechanisms, and addressing any compliance or security concerns.
Change Management
With these boundaries firmly in place we can now see how a team might quickly iterate on changes to the platform using a version controlled data project.
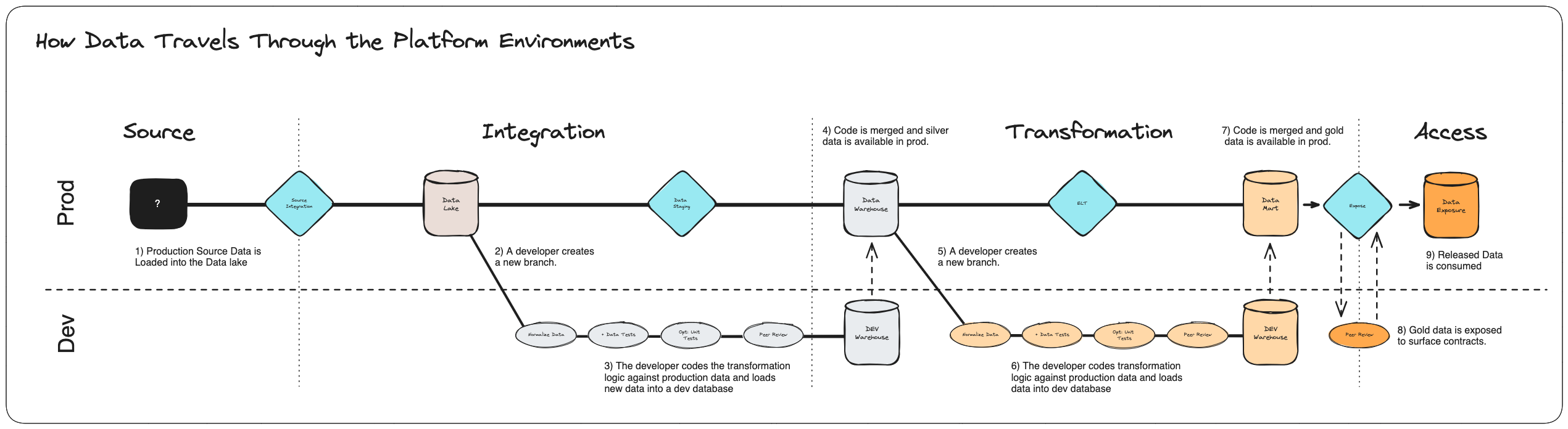
- Integration developers are introducing new and updated data to the raw data lake (bronze)
- ELT engineers work on normalization of the raw data into canonical data (silver)
- Data validation, freshness checks, and calculation unit testing is applied to the staged data (silver)
- As changed are approved the code is “released” to the production layer
- Data and/or Analytics engineers collaborate on building trusted warehouses for downstream consumption (gold)
- As changes are approved the code is released to the production layer
- Versioned APIs or database views are updated to leverage the approved changes.
- Versioning allows as needed adoption of the new or changed data.
Conclusion
By implementing these layers effectively, organizations can create a robust data platform that enables data-driven decision-making, fosters collaboration between teams, and ensures the integrity and security of the data throughout its lifecycle. Additionally, adhering to best practices such as loose coupling between data sources and platforms, standardized transformation processes, and stringent access controls helps minimize disruptions and ensures the platform’s scalability and flexibility over time ultimately leading to a better developer experience and quick delivery of data.