How Rails Informs My Approach to Data Engineering
Data Engineering
Background
I started off my programming journey with Python scripting. Python scripting was my gateway to the world of software engineering however, through a series of right-place-at-the-right-time coincidences I was introduced to Ruby on Rails. The Rails framework was eye-opening for me. The idea that asset management and project structure were predefined but loosely enforced made working with code a delight. No more did I have to spend hours configuring environments, and dependencies, and obsessing over my project structure. Now I could just focus on crafting solutions. Now people have a love/hate relationship with Ruby on Rails, but that is a discussion for another time. However, the lessons I learned from working in the framework have influenced my approach to code as a whole and taught me the value and power of establishing conventions in code projects.
Introduction
Today, we embark on a journey that merges the elegance of Convention over Configuration (CoC) with the cutting-edge capabilities of modern data warehousing tools. Picture this: a world where managing vast amounts of data is not a Herculean task, but rather a seamless process guided by software engineering best practices, infrastructure as code, and automation. Let’s dive deeper into how dbt along with the principles of CoC, can and are reshaping the landscape of data engineering.
In the ever-evolving realm of data engineering, innovation is the name of the game. Gone are the days of arduous data management processes; instead, we stand at the precipice of a new era, where tools like dbt, Snowflake, and Fivetran offer a glimpse into the future of data warehousing. But what sets these tools apart? How do they integrate with the tried-and-true principles of software development? Let’s delve deeper and uncover the answers.
The Data Build Tool
Imagine a world where data infrastructure is as malleable as code itself. This is precisely what dbt brings to the table. With its innovative approach to “data as code,” dbt allows data engineers to harness the power of version control, clear data lineage, and a superior developer experience compared to legacy tools1. Think of it as unlocking best practices enjoyed by software engineers for years, enabling us to validate, test, and deploy data pipelines with confidence.
Previous iterations of this infrastructure often have on-prem servers running DAG management software to string together multiple SQL queries, python scripts, or other commands to orchestrate a workflow in disparate systems. Large enterprise companies might have outsourced this function to proprietary products. DBT is at the forefront of a handful of tools that provide a framework using scalar languages and open-source APIs to encapsulate, share but also test and deploy these same workflows within a single framework. This new landscape might look something like the following diagram:
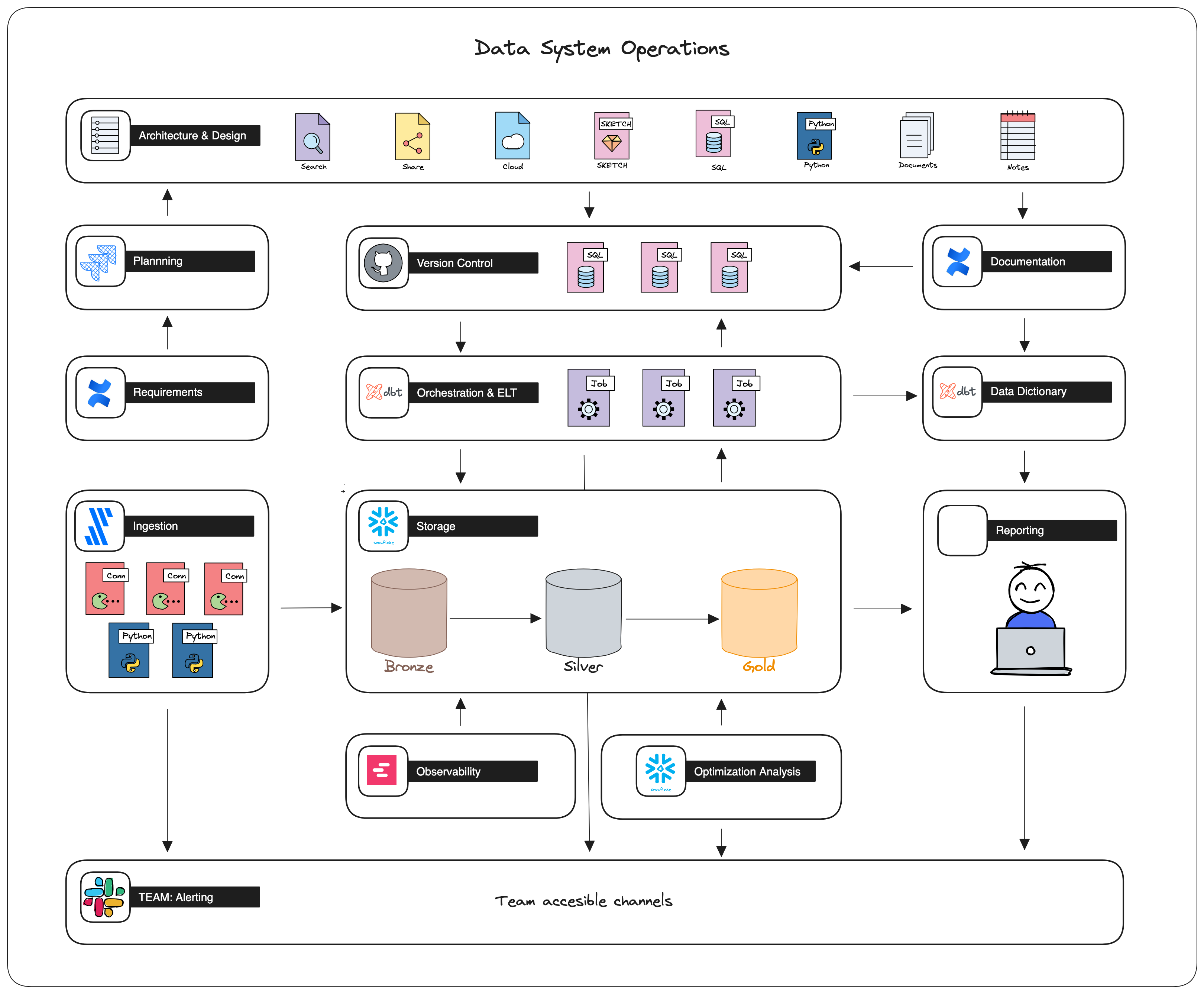
This article focuses on dbt however, this system architecture highlights some of my favorite tools. Two worth calling out before we move on are:
- Fivetran provides low and no-code solutions for integrating with data sources and managing those connections and workflows.
- Snowflake is a cloud-native managed storage solution administrated with vanilla SQL.
CoC In Data Warehousing
Rails developers swear by the principle of CoC, and for good reason. By embracing established conventions, developers can focus on building features rather than wrestling with the minutia of where to put things2. The same philosophy can apply to data warehousing. With dbt, we adhere to predefined conventions that streamline our workflows and reduce complexity, allowing us to focus on what truly matters: delivering high-quality data solutions.
The kind folks at getdbt.com offer a wealth of tried and tested strategies for getting the most out of the framework. Additionally, the open-source nature of packages allows developers to explore, execute, and build on the shoulders of their peers. As with any project, best practices provide the foundation and conventions used in these packages to facilitate this rapid innovation. These foundations are where we begin to form our internal facing conventions that best suit the needs and requirements of our projects.
TDD in DBT
Data quality is the cornerstone of any successful data warehouse. Fortunately, dbt equips us with the tools needed to maintain impeccable data integrity. Through features like built-in testing, sample data, and seed data, we can validate our data with ease3. This ensures the clarity and reliability of our data but also empowers us to catch issues early on before they escalate into larger problems.
Rails developers know the importance of properly tested code. Unit, integration, and end-to-end tests are key to allowing many developers to iterate on a single code base quickly and efficiently. This is achieved in dbt by leveraging the built-in test suite as well as unit testing complex algorithms and transformation logic by encapsulating them into reusable macros across multiple data models. With this testing in place, we can confidently trust that our math is accurate, our mappings are relevant, and our data is trustworthy. Even more so, we can now alert data engineers when anomalies are detected and take action to mitigate them.
Therefore, adequate test coverage is the first convention we introduce to any project. Peer review is likely the best way to keep developers honest in this regard, however I prefer automation wherever possible. A tried and true method that has worked well is using commit hooks to perform checks to ensure that our code is measuring up. Traditionally, I have leaned towards plugin-less approaches, however pre-commit has a library of functionality that simplifies this process beyond simple bash scripts. This API allows us to leverage custom plugins that perform the validations we need. The following snippet offers a glimpse into a typical pre-commit setup for a dbt project:
# .pre-commit-config.yaml
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v2.3.0
hooks:
- id: check-yaml
- id: end-of-file-fixer
- id: trailing-whitespace
- id: requirements-txt-fixer
- repo: https://github.com/sqlfluff/sqlfluff
rev: 2.3.5
hooks:
- id: sqlfluff-fix
additional_dependencies: ['dbt-snowflake==1.7.0', 'sqlfluff-templater-dbt']
- id: sqlfluff-lint
additional_dependencies: ['dbt-snowflake==1.7.0', 'sqlfluff-templater-dbt']
- repo: https://github.com/dbt-checkpoint/dbt-checkpoint
rev: v1.0.0
hooks:
- id: dbt-compile
- id: dbt-docs-generate
- id: check-source-has-freshness
args: ["--freshness", "error_after", "warn_after", "--"]
- id: check-model-columns-have-desc
- id: check-model-has-all-columns
- id: check-model-has-tests
args: ["--test-cnt", "2", "--"]
This is broken up into three distinct checks; General formatting, Linting, and dbt specific validations. DBT Checkpoint is the key to ensuring that minimum testing levels are achieved. If you haven’t seen it before I highly recommend it. This will ensure that our dbt project can be compiled, that models have met the minimum testing requirements, and that our properties files are in sync with our data. These checks are vital to keeping our code clean and functional. Best of all it is automated, so it removes human error from our development process. Code reviews can now focus on the functionality of our code and not get bogged down in the minutia of syntax.
This is a great example of how pre-commit can be leveraged to streamline our development process by enforcing several conventions beyond testing. I’m not sure who I am quoting here when I say “Lines are cheap, brain power is expensive.” I think what this person was saying is that clean code is easier to read and therefore use. Linting code is a simple and effective way to keep code easy to read and more importantly debug. Establishing a convention that works for your team is simple using a dbt or jinja flavored template engine for sqlfluff. I won’t bore you with the nuances of sqlfluff config as the docs are far more informative than I can be in this brief article. Needless to say implementing these two automations goes a long way in establishing well-documented conventions within a project that are automatically enforced.
Streamlining Deployment and Management with Git and dbt
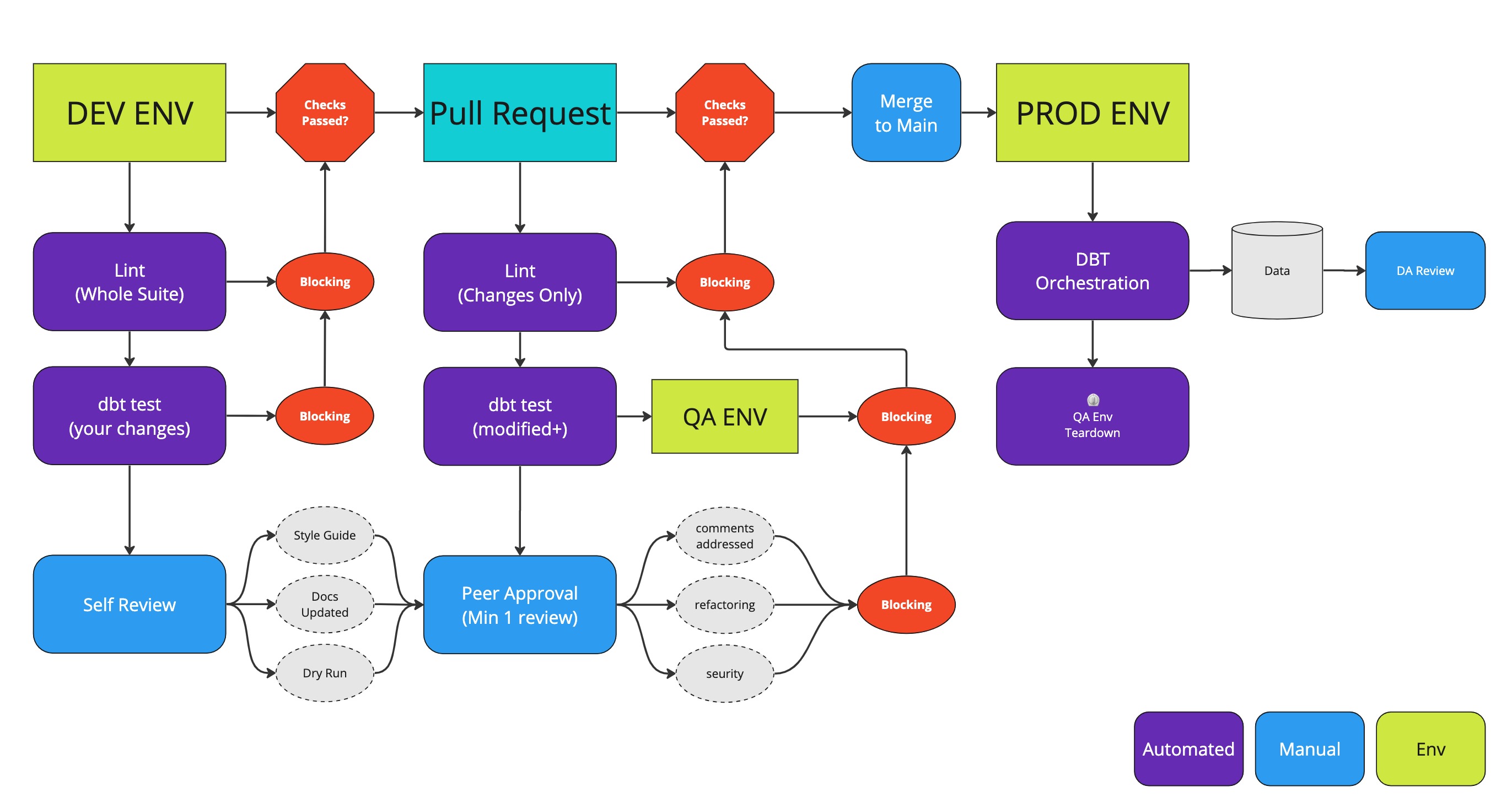
Git, the beloved version control system, paired with dbt, offers a match made in data engineering heaven. Together, they provide us with robust workflows for managing changes to our data pipeline4. From collaboration to deployment, Git and dbt ensure that our processes are seamless and efficient. And let’s not forget the concept of infrastructure as code (IAC), which allows us to manage our environments effortlessly, further enhancing our agility and productivity.
Gone are the days of siloed engineers manually QAing functional logic and data accuracy only to move on to the next task without any insight into the data drift or bug introduction. Peer-reviewed and tested code is now version-controlled and can be rolled back at any point with confidence and ease. A single framework for all engineers to operate in allows a central location for version control and peer review. Leveraging tools like linting, testing, and documentation means all engineers are rowing in the same direction and using the same tools.
Lucky for us we already installed and configured pre-commit checks to enforce our conventions at a local development level. This same configuration can be leveraged in our CI workflow using git actions. Here is an example git action workflow that performs the same pre-commit checks when a PR is created in the project repo using a prepackaged git action:
# .githb/workflows/pre-commit.yaml
name: pre-commit-checks
on:
pull_request:
push:
branches: [main]
jobs:
pre-commit-checks:
runs-on: ubuntu-latest
environment: pre-commit-env
env:
DBT_PROFILE_DIR: .
CI_PROFILE: .github/ci_profiles/profiles.yml
# additional env variables here
steps:
- uses: actions/checkout@v4
- name: Load DBT Profile
run: |
echo "COPY ci profiles.yml to root directory"
cp $CI_PROFILE ./profiles.yml
- name: Install Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
cache: pip
- name: Install Python dependencies
run: pip install -r requirements.txt
- name: Cache DBT packages
uses: actions/cache@v4
with:
path: dbt_packages
key: ${ runner.os }-dbt-packages-${ hashFiles('**/packages.yml') }
restore-keys: ${ runner.os }-dbt-packages-${ hashFiles('**/packages.yml') }
- name: Install DBT Packages
run: dbt deps
- name: Run Validations
uses: pre-commit/action@v3.0.1
Now when a data engineer creates a pull request introducing new models, macros, and properties, they can do so with confidence. Working as a team to establish these conventions ensures that we are all working in the same direction. It all comes together to ensure that our code is formatted, meets minimum requirements, and is well documented.
Conclusion
As we reach the end of our journey, one thing becomes abundantly clear: the fusion of CoC principles and modern data warehousing tools has ushered in a new era of possibility. By embracing CoC, ensuring data quality with dbt, and streamlining deployment with Git, we empower ourselves to navigate the complexities of data engineering with grace and confidence. So, fellow data enthusiasts, let us continue to push the boundaries of what’s possible, one line of code at a time.
In the words of Ruby on Rails creator David Heinemeier Hansson, “Convention over configuration is a developer’s best friend.” And in the world of data engineering, it’s a mantra worth embracing.